



TEI: Altered, Corrected, and Erroneous Texts11.3.1 Altered, Corrected, and Erroneous Texts
In the detailed transcription of any source, it may prove necessary to record various types of actual or potential alteration of the text: expansion of abbreviations, correction of the text (either by author, scribe, or later hand, or by previous or current editors or scholars), addition, deletion, or substitution of material, and similar matters. The sections below describe how such phenomena may be encoded using either elements defined in the core module (defined in chapter 3 Elements Available in All TEI Documents) or specialized elements available only when the module described in this chapter is available.
TEI: Core Elements for Transcriptional Work11.3.1.1 Core Elements for Transcriptional Work
In transcribing individual sources of any type, encoders may record corrections, normalizations, additions, and omissions using the elements described in section 3.5 Simple Editorial Changes. Representation of abbreviations and their expansions may also involve use of elements described in section 3.6 Names, Numbers, Dates, Abbreviations, and Addresses. Elements particularly relevant to this chapter include:
- abbr (縮寫) 包含任何形式的縮寫。
- add (插入) 包含由作者、抄寫者、註解者、或更正者在文本中插入的字母、單字或詞彙。
- choice (choice) 匯集文件中對於同一部分文字所有可供替換的不同標記。
- corr (更正) 包含文本中看似錯誤並加以更正過後的文字。
- del (刪除) 標記在文本中,由作者、抄寫者、註解者、或更正者刪除、標上刪除記號、或者標明為多餘或偽造的字母或單字。
- expan (縮寫還原) 包含一個縮寫詞的還原形式。
- gap (gap) 指出轉錄時被省略部分的位置,省略也許是出於 TEI標頭裡描述的編輯上的理由、也許是因為抽樣轉錄而省略、或是因為資料不明難以辨認或聽懂。
- sic (原文照錄) 包含看似錯誤但仍照實轉錄的文字 。
All of these elements bear additional attributes for specifying who is responsible for the interpretation represented by the markup, and the associated certainty. In addition, some of them bear an attribute allowing the markup to be categorized by type and source.
- att.editLike 提供屬性,描述任何已標記的學者更正或詮釋的性質。
evidence 指出支持該更動或詮釋可信度或正確性的證明 被推薦的值包含: 1] internal; 2] external; 3] conjecture - att.global.source provides attributes used by elements to point to an external source.
source specifies the source from which some aspect of this element is drawn. - att.global.responsibility provides attributes indicating the agent responsible for some aspect of the text,
the markup or something asserted by the markup, and the degree of certainty associated
with it.
cert (certainty) 表示該更動或詮釋的相關正確度。 resp (responsible party) 指出負責該更動或詮釋的代理者,例如編輯或轉錄者。 - att.typed 提供可依任何方法將元素分類或次要分類的一般屬性。
type 用合適的分類標準或類型來描述該元素。 subtype (subtype) 若有需要,提供該元素的次要分類
The specific aspect of the markup described by these attributes differs on different elements; for further discussion, see the relevant sections below, especially section 11.3.2.2 Hand, Responsibility, and Certainty Attributes.
The following sections describe how the core elements just named may be used in the transcription of primary source materials.
TEI: Abbreviation and Expansion11.3.1.2 Abbreviation and Expansion
The writing of manuscripts by hand lends itself to the use of abbreviation to shorten scribal labour. Commonly occurring letters, groups of letters, words, or even whole phrases, may be represented by significant marks. This phenomenon of manuscript abbreviation is so widespread and so various that no taxonomy of it is here attempted. Instead, methods are shown which allow abbreviations to be encoded using the core elements mentioned above.
A manuscript abbreviation may be viewed in two ways. One may transcribe it as a particular sequence of letters or marks upon the page: thus, a ‘p with a bar through the descender’, a ‘superscript hook’, a ‘macron’. One may also interpret the abbreviation in terms of the letter or letters it is seen as standing for: thus, ‘per’, ‘re’, ‘n’. Both of these views are supported by these Guidelines.
In many cases the glyph found in the manuscript source also exists in the Unicode character set: for example the common Latin brevigraph ?, standing for et and often known as the ‘Tironian et’ can be directly represented in any XML document as the Unicode character with code point U+204A (see further Character References and vi.1. Language Identification). In cases where it does not, these Guidelines recommend use of the g element provided by the gaiji module described in chapter 5 Characters, Glyphs, and Writing Modes. This module allows the encoder great flexibility both in processing and in documenting non-standard characters or glyphs, including the ability to provide detailed documentation and images for them.

this ladder
<!-- elsewhere -->
<charDecl>
?<char?xml:id="b-er">
<!-- definition for the er brevigraph -->
?</char>
?<char?xml:id="b-per">
<!-- definition for the per brevigraph -->
?</char>
</charDecl>
- ex (縮寫還原) contains a sequence of letters added by an editor or transcriber when expanding an abbreviation.
- am (abbreviation marker) contains a sequence of letters or signs present in an abbreviation which are omitted or replaced in the expanded form of the abbreviation.
As implied in the preceding discussion, making decisions about which of these various methods of representing abbreviation to use will form an important part of an encoder's practice. As a rule, the abbr and am elements should be preferred where it is wished to signify that the content of the element is an abbreviation, without necessarily indicating what the abbreviation may stand for. The ex and expan elements should be used where it is wished to signify that the content of the element is not present in the source but has been supplied by the transcriber, without necessarily indicating the abbreviation used in the original. The decision as to which course of action is appropriate may vary from abbreviation to abbreviation; there is no requirement that the same system be used throughout a transcription, although doing so will generally simplify processing. The choice is likely to be a matter of editorial policy. If the highest priority is to transcribe the text literatim (letter by letter), while indicating the presence of abbreviations, the choice will be to use abbr or am throughout. If the highest priority is to present a reading transcription, while indicating that some letters or words are not actually present in the original, the choice will be to use ex or expan throughout.
It contains any type of abbreviation. "href" https://tei-c.org/release/tei-p5-doc/zh-tw/ref-bbr.html" and If more than one expansion for the same abbreviation is to be recorded, multiple notes
may be supplied. It may also be appropriate to use the markup for critical apparatus;
an example is given in section 12.3 Using Apparatus Elements in Transcriptions.
the final d could signify the plural ending (-es, -is, -ys>) but the
singular <hi?rend="it">goode</hi> was used with the meaning <q>property</q>,
<q>wealth</q>, at this time (v. examples quoted in OED, sb. Good, C. 7, b,
c, d and 8 spec.)</note>
<choice>
?<sic>goo<abbr>?</abbr>
?</sic>
?<expan?resp="#mp"?cert="high">good<ex>e</ex>
?</expan>
</choice> I was
welbeloued
TEI: Correction and Conjecture11.3.1.3 Correction and Conjecture
ostendimus quod nutrimentum et
<choice>
?<sic>angues</sic>
?<corr>augens</corr>
</choice>.
Note that the corr element is used to provide a corrected form which is not present in the source; in the case of a correction made in the source itself, whether scribal, authorial, or by some other hand, the add, del, and subst elements described in 11.3.1.4 Additions and Deletions should be used.
As with expan and abbr, the choice as to whether to record simply that there is an apparent error, or simply
that a correction has been applied, or to record both possible readings within a choice element is left to the encoder. The decision is likely to be a matter of editorial
policy, which might be applied consistently throughout or decided case by case. If
the highest priority is to present an uncorrected transcription while noting perceived
errors in the original, the choice will typically be to use only sic throughout. If the highest priority is to present a reading transcription, while
indicating that perceived errors in the original have been corrected, the choice will
be to use only corr throughout. As with and Further information may be attached to instances of these elements by the note element and resp and cert attributes. Instances of these elements may also be classified according to any convenient
typology using the type attribute. Another information may be attached to comments by the > > > > > > >
membres maad, of generacioun And of so parfit wis a <choice?xml:id="corr117">
?<sic>wight</sic>
?<corr>wright</corr>
</choice> ywroght?
<!-- ... -->
<note?target="#corr117">This emendation of the Hengwrt copy text, based on a Latin
source and on the reading of three late and usually unauthoritative
manuscripts, was proposed by E. Talbot Donaldson in
<bibl>
<title>Speculum</title> 40 (1965) 626–33.</bibl>
</note>
?<sic>mens</sic>
?<corr>iners</corr>
</choice> que nutu dei gesta
sunt ... unde esset uiriliter
<choice?xml:id="sic-2">
?<corr>uegetata</corr>
?<sic>negata</sic>
</choice>
?<sic>mens</sic>
?<corr?type="graphSubs">iners</corr>
</choice> que nutu dei gesta sunt ... unde
esset uiriliter
<choice>
?<corr?type="graphSubs">uegetata</corr>
?<sic>negata</sic>
</choice>
?<sic>mens</sic>
?<corr?type="graphSubs">iners</corr>
?<corr?type="reversal">inres</corr>
</choice> que
nutu dei gesta sunt ...
?<p>The following codes are used to categorize corrections identified in this
transcription: <list?type="gloss">
?<label>graphSubs</label>
?<item>Substitution of a more familiar word which resembles graphically
what the scribe should be copying but which does not make sense in the
context.</item>
<!-- ... -->
</list>
?</p>
</correction>
For a given project, it may well be desirable to limit the possible values for the type or subtype attributes automatically. This is easily done but requires customization of the TEI system using techniques described in 23.3 Customization, in particular 23.3.1.3 Modification of Attribute and Attribute Value Lists, which should be consulted for further information on this topic.
parfit wis a <choice>
?<sic>wight</sic>
?<corr?resp="#mp"?source="#Gg">wyf</corr>
</choice> ywroght?
?<rdg?wit="#Hg">wight</rdg>
?<rdg?wit="#Ln #Ry2 #Ld">
<corr?resp="#ETD">wright</corr>
?</rdg>
?<rdg?wit="#Gg">
<corr?resp="#mp">wyf</corr>
?</rdg>
</app>
Like the resp attribute, the cert attribute may be used with both corr and rdg elements. When used on the rdg element, these attributes indicate confidence in and responsibility for identifying the reading within the sources specified; when used on the corr element they indicate confidence in and responsibility for the use of the reading to correct the base text. If no other source is indicated (either by the source attribute, or by the wit attribute of a parent rdg), the reading supplied within a corr has been provided by the person indicated by the resp attribute.
The text contains what appears to be wrong and corrected. "href=https://tei-c.org/release/doc/tec_tei-p5-doc/zh-tw/ref-corr.html with both If it is desired to express certainty of or responsibility for some other aspect of
the use of these elements, then the mechanisms discussed in chapter 21 Certainty, Precision, and Responsibility may be found useful. See also 11.3.2.2 Hand, Responsibility, and Certainty Attributes for further discussion of the issues of certainty and responsibility in the context
of transcription.
TEI: Additions and Deletions11.3.1.4 Additions and Deletions
Additions and deletions observed in a source text may be described using the following elements:
- add (插入) 包含由作者、抄寫者、註解者、或更正者在文本中插入的字母、單字或詞彙。
- addSpan (加入的文字段) 標記由作者、抄寫者、註解者或更正者所加入的較長連續文字之開端 (參照add) 。
- del (刪除) 標記在文本中,由作者、抄寫者、註解者、或更正者刪除、標上刪除記號、或者標明為多餘或偽造的字母或單字。
- delSpan (刪除的文字段) 標記一較長連續性文字之開端,該文字由作者、抄寫者、註解者、或更正者刪除、標上刪除記號、或者標明為多餘或偽造。
Of these, add and del are included in the core module, while addSpan and delSpan are available only when using the module defined in this chapter. These particular elements are members of the att.spanning class, from which they inherit the following attribute:
Of These, . "href= https://tei-add.html" > > > >
- att.spanning 提供元素的屬性,這些元素使用參照機制來限定某一文字段,而非包含此文字段。
spanTo 指出文字段的結尾,該文字段以帶有此屬性的元素開頭。
Further characteristics of each addition and deletion, such as the hand used, its effect (complete or incomplete, for example), or its position in a sequence of such operations may conveniently be recorded as attributes of these elements, all of which are members of the att.transcriptional class:
- att.transcriptional provides attributes specific to elements encoding authorial or scribal intervention
in a text when transcribing manuscript or similar sources.
seq (sequence) assigns a sequence number related to the order in which the encoded features carrying this attribute are believed to have occurred. status indicates the effect of the intervention, for example in the case of a deletion, strikeouts which include too much or too little text, or in the case of an addition, an insertion which duplicates some of the text already present. 實例值包含: 1] duplicate; 2] duplicate-partial; 3] excessStart; 4] excessEnd; 5] shortStart; 6] shortEnd; 7] partial; 8] unremarkable hand [att.written] points to a handNote element describing the hand considered responsible for the content of the element concerned.
at first sight. Others — and here is one of them — <add?hand="#mb">do ever</add>
improve by recognition [...]
<handNote?xml:id="mb">Max Beerbohm
holograph</handNote>
<handNote?xml:id="dhl">D H Lawrence holograph</handNote>
If deletions are classified systematically, the type attribute may be useful to indicate the classification; when they are classified by the manner in which they were effected, or by their appearance, however, this will lead to a certain arbitrariness in deciding whether to use the type or the rend attribute to hold the information. In general, it is recommended that the rend attribute be used for description of the appearance or method of deletion, and that the type attribute be reserved for higher level or more abstract classifications.

?<person?xml:id="RG">
<!-- information about Robert Graves here -->
?</person>
</listPerson>
dictionary so much as a corpus of precedents <del?hand="#RG">in the</del>:
current, obsolete, <add?hand="#RG"?place="above">cant,</add> cataphretic and
nonce-words are all included.
?<add?hand="#RG"?place="above">for an abridgement</add>
</del> in explanation...
<subst>
?<add>T</add>
?<del>t</del>
</subst>he expressed
The add and del elements defined in the core module suffice only for the description of additions and deletions which fit within the structure of the text being transcribed, that is, which each deletion or addition is completely contained by the structural element (paragraph, line, division) within which it occurs. Where this is not the case, for example because an individual addition or deletion involves several distinct structural subdivisions, such as poems or prose items, or otherwise crosses a structural boundary in the text being encoded, special treatment is needed. The addSpan and delSpan elements are provided by this module for that purpose. (For a general discussion of the issue see further 20 Non-hierarchical Structures).
The and The text deleted must be at least partially legible, in order for the encoder to be
able to transcribe it. If all of part of it is not legible, the gap element should be used to indicate where text has not been transcribed, because it
could not be. The unclear element described in section 11.3.3.1 Damage, Illegibility, and Supplied Text may be used to indicate areas of text which cannot be read with confidence. See further
section 11.3.1.7 Text Omitted from or Supplied in the Transcription and section 11.3.3.1 Damage, Illegibility, and Supplied Text. The text deleted must be at least edited and accessible, in order to be able to translate it. If all of it is not part of "gi" message, the Substitution of one word or phrase for another is perhaps the most common of all phenomena
requiring special treatment in transcription of primary textual sources. It may be
simply one word written over the top of another, or deletion of one word and its replacement
by another written above it by the same hand on the same occasion; the deletion and
replacement may be done by different hands at different times; there may be a long
chain of substitutions on the same stretch of text, with uncertainty as to the order
of substitution and as to which of many possible readings should be preferred. A special case of a substitution may consist of a superfluous word or phrase that
is silently replaced by some addition. E.g. a scribe abandons a word (without indicating
it should be deleted), and then writes a replacement word immediately after. Here
the encoder may interpret this as an ‘unmarked’ deletion which can then be combined
with a corresponding addition to a substitution.
?scribe="Helgiólafsson"/>
<!-- ... -->
<body>
?<div>
<!-- text here -->
?</div>
?<addSpan?n="added gathering"?hand="#heol"
spanTo="#p025"/>
?<div>
<!-- text of first added poem here -->
?</div>
?<div>
<!-- text of second added poem here -->
?</div>
?<div>
<!-- text of third added poem here -->
?</div>
?<div>
<!-- text of fourth added poem here -->
?</div>
?<anchor?xml:id="p025"/>
?<div>
<!-- more text here -->
?</div>
</body>
<delSpan?spanTo="#EPdelEnd"?resp="#EP"
?rend="strikethrough"/>
<l>To where Saint Mary Woolnoth kept the time,</l>
<l>With a dead sound on the final stroke of nine.</l>
<anchor?xml:id="EPdelEnd"/>
<l>There I saw one I knew, and stopped him, crying "Stetson!</l>...
?<delSpan?rend="verticalStrike"
spanTo="#delend01"/> Tis moonlight
<del>upon</del>
?<add>over</add> Oman's sky
</l>
<l>Her isles of pearl look lovelily<anchor?xml:id="delend01"/>
</l>TEI: Substitutions11.3.1.5 Substitutions
Using the subst element, the example at the end of the last section might be encoded as follows:
?<delSpan?rend="verticalStrike"
spanTo="#delend02"/> Tis moonlight
<subst>
<del>upon</del>
<add>over</add>
?</subst> Oman's sky
</l>
<l>Her isles of pearl look lovelily<anchor?xml:id="delend02"/>
</l>
with <subst>
?<del?seq="1">this</del>
?<del?seq="2">
<add?seq="1">such a</add>
?</del>
?<add?seq="2">a</add>
</subst> system, to appreciate its advantages.
fann'd
<substJoin?target="#change1 #change2"/>
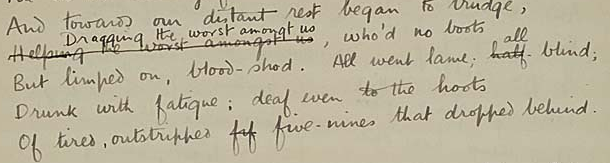
<l>
?<subst>
<del>Helping the worst amongst us</del>
<add>Dragging the worst amongt
us</add>
?</subst>, who'd no boots
</l>
<l>But limped on, blood-shod. All went lame; <subst>
<del?status="shortEnd">half-</del>
<add>all</add>
?</subst> blind;</l>
<l>Drunk with fatigue ; deaf even to the hoots</l>
<l>Of tired, outstripped <del>fif</del> five-nines that dropped
behind.</l>
TEI: Cancellation of Deletions and Other Markings11.3.1.6 Cancellation of Deletions and Other Markings
An author or scribe may mark a word or phrase in some way, and then on reflection decide to cancel the marking. For example, text may be marked for deletion and the deletion then cancelled, thus restoring the deleted text. Such cancellation may be indicated by the restore element:
An object or record may make a word or object in some way, and then on recall decide to recall the mark. For example, text may be made for delection and the delection then recall, among others the deleted text. Such communication may be identified by the This element bears the same attributes as the other transcriptional elements. These
may be used to supply further information such as the hand in which the restoration
is carried out, the type of restoration, and the person responsible for identifying
the restoration as such, in the same way as elsewhere. Another feature commonly encountered in manuscripts is the use of circles, lines,
or arrows to indicate transposition of material from one point in the text to another.
No specific markup for this phenomenon is proposed at this time. Such cases are most
simply encoded as additions at the point of insertion and deletions at the point of
encirclement or other marking.
TEI: Text Omitted from or Supplied in the Transcription11.3.1.7 Text Omitted from or Supplied in the Transcription
Where text is not transcribed, whether because of damage to the original, or because it is illegible, or for some other reason such as editorial policy, the gap core element may be used to register the omission; where such text is transcribed, but the editor wishes to indicate that they consider it to be superfluous, for example because it is an inadvertent scribal repetition or an interpolation from another source, the surplus element may be used in preference. Where the editor believes text to be interpolated but genuine, the secl element may be used instead. Where text not present in the source is supplied (whether conjecturally or from other witnesses) to fill an apparent gap in the text, the supplied element may be used.
Where in text is not omitted, because of the layout of the TEI logo, or because it is illegible, or for some other reason such as economic policy, the
- gap (gap) 指出轉錄時被省略部分的位置,省略也許是出於 TEI標頭裡描述的編輯上的理由、也許是因為抽樣轉錄而省略、或是因為資料不明難以辨認或聽懂。
reason (reason) 說明省略的原因。屬性值的例子有sampling、、inaudible、irrelevant、cancelled、cancelled and illegible。 被推薦的值包含: 1] cancelled (cancelled); 2] deleted (deleted); 3] editorial (editorial); 4] illegible (illegible); 5] inaudible (inaudible); 6] irrelevant (irrelevant); 7] sampling (sampling) agent (agent) 若省略是由於內容遭受損毀,且可識別損毀原因,則針對損毀原因加以分類。 實例值包含: 1] rubbing (rubbing); 2] mildew (mildew); 3] smoke (smoke) - surplus (surplus) marks text present in the source which the editor believes to be superfluous
or redundant.
reason one or more words indicating why this text is believed to be superfluous, e.g. repeated, interpolated etc. - secl (secluded text) Secluded. Marks text present in the source which the editor believes
to be genuine but out of its original place (which is unknown).
reason one or more words indicating why this text has been secluded, e.g. interpolated etc. - supplied (supplied) 指出一段由轉錄者或編者添加的補充文字,添加的原因是該位置的文字無法被辨認,也許是因為來源文件的損壞或內容遺失、或是任何其他原因導致難以辨認。
reason 說明該文件當時必須補充的原因。
?unit="word"/>Sydney Smith
As noted above, the gap element should only be used where text has not been transcribed. If partially legible text has been transcribed, one of the elements damage and unclear should be used instead (these elements are described in section 11.3.3.1 Damage, Illegibility, and Supplied Text); if the text is legible and has been transcribed, but the editor wishes to indicate that they regard it is superfluous or redundant, then the element surplus may be used in preference to the core element sic used to indicate text regarded as erroneous.
"Wef" https://tei-c.org/release/doc-doc/zh-html/ref-gap.html"
Amongst the many examples cited in Hans Krummrey & Silvio Panciera's classic text on the editing of epigraphic inscriptions is the following. In a late classical inscription, the form ‘dedikararunt’ is encountered. The editor may choose any of the following three possibilities:
- mark this as an erroneous form
- additionally supply a corrected form
- indicate that the erroneous form contains surplus characters which the editor wishes to suppress
tradimento</surplus>
</l>
<l?n="5">sì com' l'uccellator prende l'uccello</l>
<gap/>
<l?n="43">e lettere dintorno che diriano <surplus?reason="interpolated">in questa
guisa</surplus>
</l>
<l?n="44">Più v'amo, d?a, che non faccio Deo</l>
<supplied?reason="illegible"?resp="#msm"
?source="#Ry2">very humble
Servt</supplied> Sydney Smith















发表评论